|
|
 |
Meta-Information
|
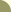 |
|
Meta-information is often explained as "information about information". This definition is succinct
but borders on tautology. We looked around the Web for a better explanation, and found this one, which is interesting because it at least attempts to explain why we would want to create meta-information -- in this case the focus is on using meta-information to help judge information quality:
"Meta-information answers questions about data provenance and fitness for use. Examples of meta-information include the following.
1. Data quality: resolution, accuracy, measurement devices, software and hardware used to gather the samples
2. Spatial referencing: coordinate systems, datums, projection systems, geoid
3. Timeliness of data: currency, frequency of collection, frequency of change
4. Lineage: the collection agency, sampling design, sampling methodology, processing methods."
quoted from:
British Columbia Ministry of Environment, Lands & Parks
|
|
 |
|
 |
|
Mining Tools
Computer Aided Information Hierarchies
A step short of true text data mining perhaps, but nonetheless interesting, is the use of computer tools for generation of meta-information, or information about information. Sometimes computers are used to derive thematic overviews of a document collection, or in a similar pursuit, the creation of a computer aided information hierarchy. In these applications, the goal is to get above a mountain of documents, so to speak, and get the lay of the land. Finding and mapping the patterns and clusters inherent in a data set can make that data set easier for a person to organize and use.
A Yahoo! or LookSmart type of IR system is based on a set of pre-defined categories that represent subjects presumed to be of interest to people. Then, Web pages are organized according to those categories. But, for any particular collection of documents it is unlikely that pre-defined categories will be a good fit. If the categories are defined too narrowly, relationships between documents may be obscured. If too many of the documents fit into the same category, the classification system will be of limited assistance to people using the collection for IR.
One answer is to eschew pre-defined categories, and have the documents categorize themselves. "There's been quite a bit of interest in document clustering, and finding ways to visualize the resulting clusters," Hearst says. To find natural document clusters, "you can pair them up, do pair-wise comparisons and see which ones are the most similar, then do comparisons of those pairs, iteratively, to find groups of documents that are similar to each other. You might actually come up with groups of things that are recognized, but that you wouldn't necessarily have thought of making into a category in advance."
"Let's say you have two sets of articles about cars. One set is about electric and other alternative energy cars. The other set of articles is about automotive safety, and includes things like congressional hearings, litigation and so on. If you do this query:
'auto safety, car'
versus another one like this:
'auto safety, electric'
you get back two sets of documents. Each set of 50 documents is clustered into, say, five clusters. Some of the clusters overlap and some don't. How do they overlap? Because some of them talk about imports and exports. But how do they differ? For one thing, in the results from the electric car query you get "California, gas-saving, hybrid car" and that sort of thing. What do you get in the safety cluster that you don't get in the electric one? You get congressional hearings, and litigation clusters. But where would you put these documents if you were putting them in a hierarchy? Would you put them under "auto"? Would you put them under "alternative energy"? Would you put them under "safety in an auto"? If there's an airplane safety section, does the auto safety section go near there? Or does it go near the auto section? Partly because documents are made up of several different topics simultaneously I think it can be advantageous to let the data decide what the groupings should be. The point is that there are multiple ways to analyze the same information."
Hearst says that the algorithms that extract themes and clusters from document sets are good at that task, but problems remain. For example, topic clusters extracted by computer analysis tend to be at varying levels of description. "You might get one cluster of documents that talk in general about legal issues, and another cluster that is very specific, say, fuel cell research advances. Also, the clusters require some interpretation. Somebody needs to look at the cluster and the words that are central to it and say, 'what's this cluster really about?' A lot of times in a user interface, for example, people aren't really interested in doing that."
"But after the clustering analysis is done and you get a hierarchical organization to start with, then the user can go and clean it up and rearrange it, which is a lot less work then starting from scratch. Then, as you get new documents you can have them automatically assigned.
So you've turned the clusters into a nice category hierarchy. You've taken one of these thematic groupings and turned it into more like a Yahoo! directory, but a Yahoo! directory that represents your information. Then when you get a new document you can automatically use a text categorization algorithm to assign it to one of the categories." This idea has been implemented by Mehran Sahami of E.piphany, a student Hearst formerly helped advise.
So, clusters aren't the same as categories. Clusters are based on similarities found by the computerized analysis of the documents in the collection. Categories are pre-assigned groupings designed to be meaningful (and helpful) to people. Because categories are pre-assigned without reference to the content of the document collection it's likely that some categories will have many documents while other categories are empty.
Hearst explains, "you could have a bunch of categories about zebras, but if all your articles are about cars, a lot of the zebra categories are empty. Whereas, with clustering, the clusters are a function of the data so whatever groups you have are because those documents are present within the groups." The process begins with clustering, an automated process and therefore less labor intensive. Then a person adapts the clusters into a category system customized to be appropriate for the particular document collection. Ideally, the resulting categories will be reasonably well balanced in terms of the number of documents in each category, and will be labeled at a uniform level of description.
A Tool For Experts
Marti Hearst sees a wide variety of potential applications for text data mining, but they have one aspect in common: they don't rely on total automation of the information task, but instead aim to create a kind of feedback loop between computer based tools and an expert human operator. The tools help the expert get through a large body of information, and to keep track of where they've been and what they've been doing. The expert user gives direction to the process by filtering out spurious results and analyzing the significance of patterns that the computer finds.
"It's my view that it will be a tool for experts in their area trying to do very knowledge intensive tasks" says Hearst. "I could imagine, however, that after a tool like this has been used awhile, that people will come up with general strategies that are useful for making certain kinds of discoveries and then this could be put into templates (or whatever). Then less expert people (or people with less time) could apply it."
"You could imagine that somebody could come up with strategies that work well for investigative reporting. That will take awhile. I don't know what they will look like. But after enough people have tried doing this, maybe some useful strategies will appear and then less expert users could just apply them.
However, it still probably wouldn't be fully automatic."
Next » Mining Messages.
Copyright © 1999, 2000 media.org.
|
|